
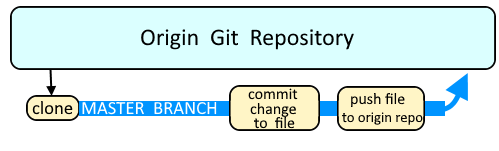
The most basic way to use Git is to use the git clone command to clone an origin Git repository (such as example.git) to a directory on your PC (such as /home/john.doe/git), make a change to a file in the cloned repository on your PC (such as example.txt), use the git commit command to commit the change to the file, and to then use the git push command to upload the file to the origin Git repository.
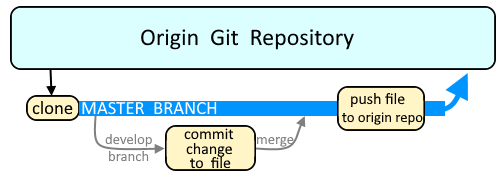
Branches are used as an isolated way to make changes to files in a repository. A common example would be to create a new branch using the git branch or git checkout command, switch to the new branch using the git checkout command, make a change to a file, commit the change using the git commit command, and then merge the branch to the master branch using the git merge command.
Let's say you create a new file in the directory of the cloned repository.
touch foo.txt
The git status command will now show that foo.txt is an untracked file.
~]# git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# foo.txt
The git add command can be used to add a file to the currently selected branch of the cloned repository. In this example, foo.txt will be added.
git add foo.txt
The git status command will now show that foo.txt is ready to be committed. You would then commit the new file.
~]# git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: foo.txt
Adding multiple files in a directory
Let's say the "test" directory contains two (or more) files.
test/foo.txt
test/bar.txt
Adding the test directory will add every file below the test directory.
git add test
Adding directories
Directories are not tracked in git. For example, let say you create a directory named fooBar.
mkdir fooBar
And add the fooBar directory.
git add fooBar
The git status command will not contain "fooBar". This is because git tracks files, not directories.
git status
Did you find this article helpful?
If so, consider buying me a coffee over at 