
Prometheus is a system used to
- Collect metrics (e.g. memory, CPU) - This is often referred to as "scraping metrics"
- Store the metrics, for example, in object storage, such as an Amazon Web Services S3 Bucket
- Configure conditions that should create an alert (e.g. high CPU or high memory usage)
For example, Prometheus can be used to gather metrics from servers, virtual machines (VMs), databases, containers (e.g. Docker, OpenShift), messaging (e.g. IBM MQ, RabbitMQ), and the list goes on. Then the metrics could be stored in object storage, such as an Amazon Web Services (AWS) S3 Bucket.
Often, an Observability system such as Kibana is used to display the metrics with a UI that is used to display query the metrics, for example, to find systems with high CPU or memory usage.
Also, an alerting system such as Alert Manager is often used to create alerts when a certain condition is met, such as a system with high CPU or high memory usage. The alerting system would route alerts to certain targets, such as an SMTP email server or OpsGenie.
The kubectl get PrometheusRules (Kubernetes) or oc get PrometheusRules (OpenShift) command can be used to list the Prometheus Rules.
~]$ oc get PrometheusRules --namespace openshift-monitoring
NAME AGE
alertmanager-main-rules 692d
cluster-monitoring-operator-prometheus-rules 692d
kube-state-metrics-rules 692d
kubernetes-monitoring-rules 692d
node-exporter-rules 692d
prometheus-k8s-prometheus-rules 692d
prometheus-k8s-thanos-sidecar-rules 692d
prometheus-operator-rules 692d
telemetry 692d
thanos-querier 692d
Each Prometheus Rule will almost always contain multiple alerts. For example, if you view the YAML for a particular Prometheus Rule (alertmanager-main-rules in this example), the rule contains multiple alerts.
~]$ oc get PrometheusRule alertmanager-main-rules --namespace openshift-monitoring --output yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
creationTimestamp: "2023-07-07T15:43:12Z"
generation: 2
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/managed-by: cluster-monitoring-operator
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: openshift-monitoring
app.kubernetes.io/version: 0.26.0
prometheus: k8s
role: alert-rules
name: alertmanager-main-rules
namespace: openshift-monitoring
resourceVersion: "433329758"
uid: 1b98ab31-7439-4f52-9f48-c04a696979c3
spec:
groups:
- name: alertmanager.rules
rules:
- alert: AlertmanagerFailedReload
annotations:
description: Configuration has failed to load for {{ $labels.namespace }}/{{
$labels.pod}}.
runbook_url: https://github.com/openshift/runbooks/blob/master/alerts/cluster-monitoring-operator/AlertmanagerFailedReload.md
summary: Reloading an Alertmanager configuration has failed.
expr: |
# Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
max_over_time(alertmanager_config_last_reload_successful{job=~"alertmanager-main|alertmanager-user-workload"}[5m]) == 0
for: 10m
labels:
severity: critical
- alert: AlertmanagerMembersInconsistent
annotations:
description: Alertmanager {{ $labels.namespace }}/{{ $labels.pod}} has only
found {{ $value }} members of the {{$labels.job}} cluster.
summary: A member of an Alertmanager cluster has not found all other cluster
members.
expr: |
# Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
max_over_time(alertmanager_cluster_members{job=~"alertmanager-main|alertmanager-user-workload"}[5m])
< on (namespace,service) group_left
count by (namespace,service) (max_over_time(alertmanager_cluster_members{job=~"alertmanager-main|alertmanager-user-workload"}[5m]))
for: 15m
labels:
severity: warning
- alert: AlertmanagerFailedToSendAlerts
annotations:
description: Alertmanager {{ $labels.namespace }}/{{ $labels.pod}} failed
to send {{ $value | humanizePercentage }} of notifications to {{ $labels.integration
}}.
runbook_url: https://github.com/openshift/runbooks/blob/master/alerts/cluster-monitoring-operator/AlertmanagerFailedToSendAlerts.md
summary: An Alertmanager instance failed to send notifications.
expr: |
(
rate(alertmanager_notifications_failed_total{job=~"alertmanager-main|alertmanager-user-workload"}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job=~"alertmanager-main|alertmanager-user-workload"}[5m])
)
> 0.01
for: 5m
labels:
severity: warning
- alert: AlertmanagerClusterFailedToSendAlerts
annotations:
description: The minimum notification failure rate to {{ $labels.integration
}} sent from any instance in the {{$labels.job}} cluster is {{ $value |
humanizePercentage }}.
runbook_url: https://github.com/openshift/runbooks/blob/master/alerts/cluster-monitoring-operator/AlertmanagerClusterFailedToSendAlerts.md
summary: All Alertmanager instances in a cluster failed to send notifications
to a critical integration.
expr: |
min by (namespace,service, integration) (
rate(alertmanager_notifications_failed_total{job=~"alertmanager-main|alertmanager-user-workload", integration=~`.*`}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job=~"alertmanager-main|alertmanager-user-workload", integration=~`.*`}[5m])
)
> 0.01
for: 5m
labels:
severity: warning
- alert: AlertmanagerConfigInconsistent
annotations:
description: Alertmanager instances within the {{$labels.job}} cluster have
different configurations.
summary: Alertmanager instances within the same cluster have different configurations.
expr: |
count by (namespace,service) (
count_values by (namespace,service) ("config_hash", alertmanager_config_hash{job=~"alertmanager-main|alertmanager-user-workload"})
)
!= 1
for: 20m
labels:
severity: warning
- alert: AlertmanagerClusterDown
annotations:
description: '{{ $value | humanizePercentage }} of Alertmanager instances
within the {{$labels.job}} cluster have been up for less than half of the
last 5m.'
summary: Half or more of the Alertmanager instances within the same cluster
are down.
expr: |
(
count by (namespace,service) (
avg_over_time(up{job=~"alertmanager-main|alertmanager-user-workload"}[5m]) < 0.5
)
/
count by (namespace,service) (
up{job=~"alertmanager-main|alertmanager-user-workload"}
)
)
>= 0.5
for: 5m
labels:
severity: warning
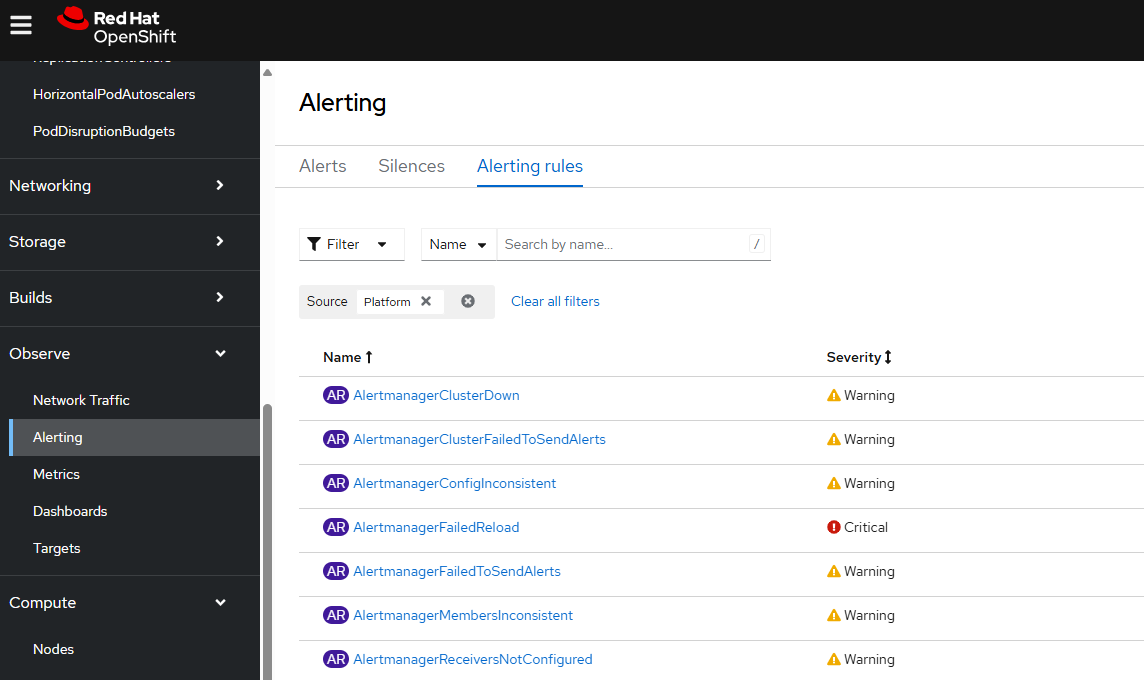
Or in the OpenShift console, at Observe > Alerting > Alerting rules the alerts in each Prometheus Rule will be listed.
Did you find this article helpful?
If so, consider buying me a coffee over at 