
If you are not familiar with the oc command, refer to OpenShift - Getting Started with the oc command
When pods are evicted from a node and the node is marked as unschedulable, such as when using the oc adm drain command to evict pods from a node and marking the node as unschedulable or when updating OpenShift to a new version, the pods running on the nodes are killed via SIGKILL and will be scheduled to run on a different node without first checking if there is a replica of the pod running on a different node.
With Pod Disruption Budgets:
- If there is NOT a replica of the pod running on a different node, the pod will not be allowed to be evicted/terminated
- If there is a replica of the pod running on a different node, the eviction and termination of a pod from a node is graceful
The graceful eviction looks like this:
- Gracefully terminate any connections to the pod
- Send SIGTERM to the pods containers so that the containers can gracefully terminate and shut down
- If the containers in the pod does not gracefully terminate and shut down after a period of time, SIGKILL will be sent to the containers to kill the containers, forcing them to shut down
For example, let's say you have a Deployment that is configured with 1 replica.
~]# oc get deployment my-deployment --output yaml
spec:
replicas: 1
Which means there should be a single pod. Notice in this example that the pod is running on node worker-hsjrp.
~]# oc get pods --output wide --namespace my-project
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED MODE
my-pod-9mzm2 1/1 Running 0 8d 10.142.118.51 worker-hsjrp <none>
Now let's imagine there is some issue with the node. Perhaps the node unexpectedly goes down. Or perhaps someone mistakenly or intentionally drained the node, evicting the pods from the node. This eviction/termination is not graceful and instead is like a quick SIGKILL.
~]# oc adm drain node worker-hsjrp
node/my-node-worker-lk5vm cordoned
evicting pod my-pod-9mzm2
pod/my-pod-9mzm2 evicted
node/my-node-worker-lk5vm drained
Let's say my-deployment has the following label.
metadata:
labels:
app: my-deployment
Let's see how we can use Pod Disruption Budgets. For example, let's say you have the following YAML file which specifies that pods in my-namespace should always have a minimum of 1 replica. Notice spec.selector: {} in this example. This will cause the Pod Disruption Budget to be applied to all pods in the namespace.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-pod-disruption-budget
namespace: my-namespace
spec:
minAvailable: 1
selector: {}
Notice in this example that the Pod Disruption Budget will be applied to pod that have label region: east and environment: production.
Check out my article FreeKB - OpenShift - matchLabels vs matchExpressions for more details on matchLabels and matchExpressions.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-pod-disruption-budget
namespace: my-namespace
spec:
minAvailable: 1
selector:
matchLabels:
region: east
environment: production
Or matchExpressions can be used.
Check out my article FreeKB - OpenShift - matchLabels vs matchExpressions for more details on matchLabels and matchExpressions.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-pod-disruption-budget
namespace: my-namespace
spec:
minAvailable: 1
selector:
matchExpressions:
- { key: region, operator: In, values: [east] }
- { key: environment, operator: NotIn, values: [dev] }
The oc apply command can be used to create the Pod Disruption Budget.
oc apply -f PodDisruptionBudget.yaml
Or in the OpenShift console, at Workloads > PodDisruptionBudgets you can select Create PodDisruptionBudget.
The oc get PodDisruptionBudgets command can be used to list Pod Distribution Budgets. Notice in this example that ALLOWED DISRUPTIONS is 1. Allowed Disruption is a boolean that will either be 0 or 1, where 0 means the Pod Disruption Budget is NOT being applied to any pods and 1 means the Pod Disruption Budget is being applied to one or more pods.
~]$ oc get PodDisruptionBudgets --namespace my-namespace
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
my-pod-disruption-budget 1 N/A 1 26s
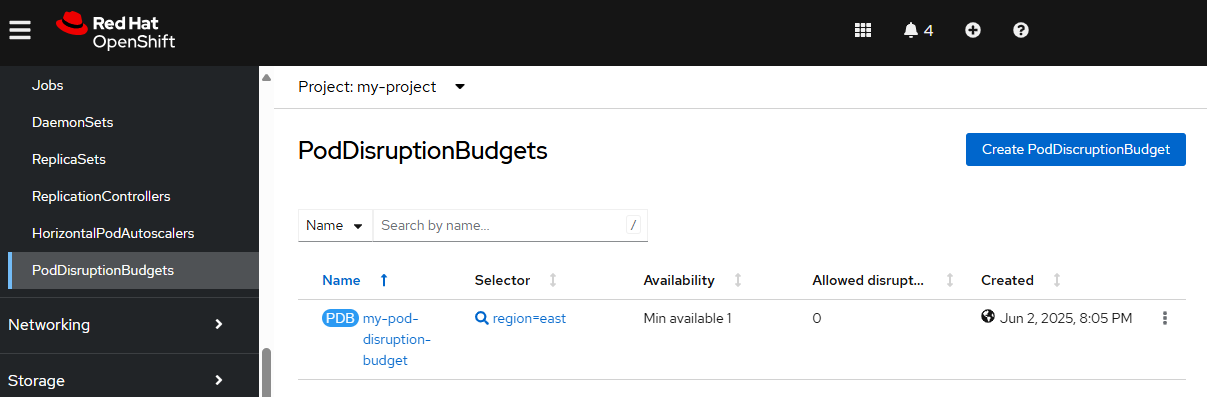
Or in the OpenShift console, at Workloads > PodDisruptionBudgets you can view the Pod Disruption Budgets.
Let's say there are 3 nodes and all 3 nodes are Ready.
~]$ oc get nodes
NAME STATUS ROLES AGE VERSION
worker-4nd2v Ready compute,worker 621d v1.29.10+67d3387
worker-jld8v Ready compute,worker 621d v1.29.10+67d3387
worker-tk6gm Ready compute,worker 621d v1.29.10+67d3387
Now let's try to drain the pod from the node using the oc adm drain command. Nice - the pod cannot be evicted from the node! This is happening because the deploy / replica set / pod is configured with 1 replica and the pod is running on the node that we are trying to drain.
~]$ oc adm drain worker-4nd2v --pod-selector app=my-deployment
node/worker-4nd2v cordoned
evicting pod my-namespace/my-pod-gqfs2
error when evicting pods/"my-pod-gqfs2" -n "my-namespace" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
Be aware that the oc adm drain command will cordon the node which means pods can no longer be scheduled on the node.
~]$ oc get nodes
NAME STATUS ROLES AGE VERSION
worker-4nd2v Ready,SchedulingDisabled compute,worker 621d v1.29.10+67d3387
worker-jld8v Ready compute,worker 621d v1.29.10+67d3387
worker-tk6gm Ready compute,worker 621d v1.29.10+67d3387
So you'll want to uncordon the node so that pods can be scheduled to run on the node.
oc adm uncordon worker-4nd2v
Let's say your deployment has 2 replicas.
~]# oc get deployment my-deployment --output yaml
spec:
replicas: 2
And the pods are running on different worker nodes.
~]$ oc get pods --output wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-pod-7vj6h 1/1 Running 0 21s 10.131.1.131 worker-2xqdt <none> <none>
my-pod-gqfs2 1/1 Running 0 24h 10.128.2.67 worker-4nd2v <none> <none>
Now when you drain the node the pod is gracefully evicted from the pod. Cool.
~]$ oc adm drain worker-4nd2v --pod-selector app=my-deployment
node/worker-4nd2v cordoned
evicting pod my-namespace/my-pod-gqfs2
pod/my-pod-gqfs2 evicted
node/worker-4nd2v drained
And a new pod was spawned. Perfect.
~]$ oc get pods --output wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-pod-42zq4 1/1 Running 0 32s 10.131.1.132 my-worker-2xqdt <none> <none>
my-pod-7vj6h 1/1 Running 0 4m 10.131.1.131 my-worker-2xqdt <none> <none>
You'll want to uncordon the node so that pods can be scheduled to run on the node.
oc adm uncordon worker-4nd2v
Did you find this article helpful?
If so, consider buying me a coffee over at 